بهینهسازی خودکارِ مهارتها، SkillOpt
چند سال پیش یکی از مهمترین دغدغههای استفاده از AI این سوالها بود: «کدوم مدل رو استفاده کنیم؟» یا «چجوری پرامپت بهتری بنویسیم؟»
حالا سوال مهمتر اینه: «این مدل با چه skillهایی کار میکنه، و کی کیفیتشون رو تضمین میکنه؟»
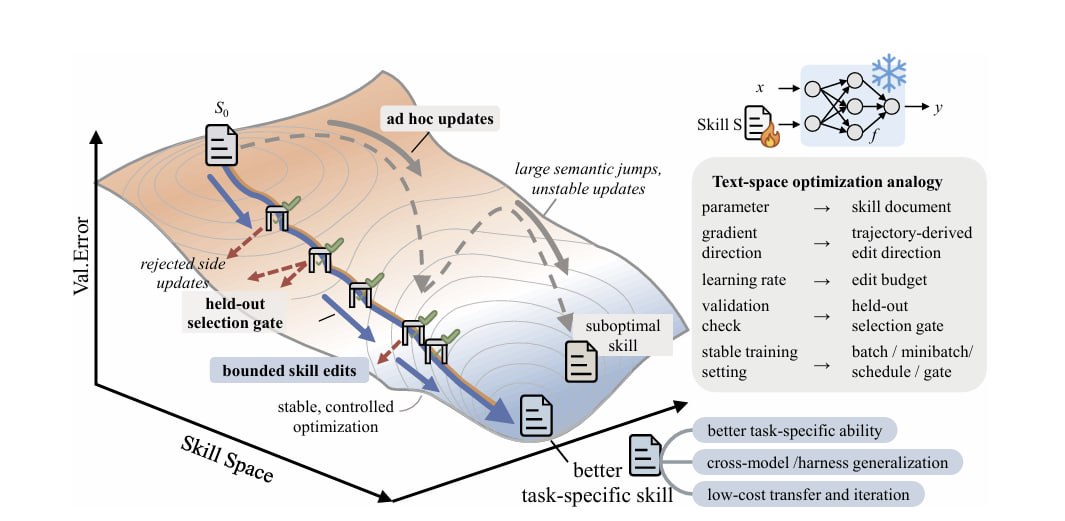
خروجی یه پروژهی تحقیقاتی مشترک Microsoft و چند دانشگاه چینی شده SkillOpt که این هفته بهصورت کدباز منتشر شد. ایدهاش سادهست: به جای fine-tune کردن مدل، فایل skill رو train کن.
یعنی یه فایل Markdown به عنوان trainable parameter یه agent frozen در نظر گرفته میشه. و optimizer، مسیر حل مسئله رو تحلیل میکنه، تغییرات ساختارمند پیشنهاد میده، و فقط اگه روی مرحله ارزیابی، بهتر شده بود، تغییرات رو قبول میکنه.
خروجی نهایی؟ یه best_skill.md بین ۳۰۰ تا ۲۰۰۰ توکن. بدون تغییر وزن مدل، بدون overhead در inference. نتایج تجربیشون روی ۵۲ از ۵۲ سلول ارزیابی بهترین یا مساوی بهترین بوده. روی GPT-5.5 بهطور میانگین +۲۳.۵ امتیاز نسبت به حالت بدون skill.
اما به نظرم مهمتر از خود ابزار، پیامشه:
اسکیل خوب میتونه خروجی یه مدل معمولی رو خیلی بهتر کنه. اسکیل بد میتونه خروجی یه مدل قوی رو خراب کنه. و اسکیل بدون validation و lifecycle، دیر یا زود تبدیل میشه به همون بدهی فنی قدیمی، فقط این بار در لباس AI.
اگه ۲۰ دقیقه وقت دارید و میخواید بدونید این چرخه بهینهسازی، چجوری کار میکنه، چه فرقی با prompt tuning معمولی داره، و چرا governance روی اسکیلها برای تیمهای انترپرایز جدیه، نسخهی مفصلتر رو روی بلاگ بخونید.
🔗لینک مطلب کامل روی بلاگ خودم